When LLMs Judge LLMs
- —Abstract
- —Between Experiments
- 1.Project Overview
- 2.Scenario 1 — Baseline
- 3.Scenario 2 — Name Blind
- 4.Scenario 3 — Evaluator Has Docs
- 5.Scenario 4 — Generator Has Docs
- 6.Scenario 5 — Both Have Docs
- A.Generator Prompts
- B.Scenario 1 — Generated Instructions
- C.Evaluation Prompts I
- D.Evaluation Prompts II
- E.Scenario 4 — Generated Instructions
- F.Generator Prompt Scenarios 4 & 5
We are increasingly overloaded by information we want to process, and this is one of the reasons why AI and large language models have become part of everyday workflows. We use them to summarize texts, explain complex topics, and help us understand, review, or judge difficult material. At the same time, we also use LLMs to generate text, improve writing, and produce better outputs for a wide range of personal and professional scenarios.
Putting these two trends together, large language models have quietly become the first reader in more and more workflows: screening job applications, evaluating proposals, summarizing reports, or scoring student work. This creates a loop that most practitioners have not fully questioned: if one LLM writes the text and another LLM evaluates it, does it matter which models are in those roles?
I am running a series of experiments to answer this question. In my studies, I use five frontier models — ChatGPT, Gemini, Grok, DeepSeek, and Claude — in a two-phase setup. In the first phase, the models generate answers or summaries. In the second phase, all models evaluate all generated outputs in an LLM-as-Judge setting.
In the first experiment, I used World War II — a topic far enough in the past, and so extensively studied, that we expect broad historical consensus and limited/no divergence across models. Yet the results showed that the choice of generator model clearly matters. Systematic and reproducible cross-model evaluation bias emerged across repeated runs: some models were consistently judged more favourably than others. This means that when automated judgment replaces human review, both the generator model and the evaluator model can introduce measurable advantages or disadvantages.
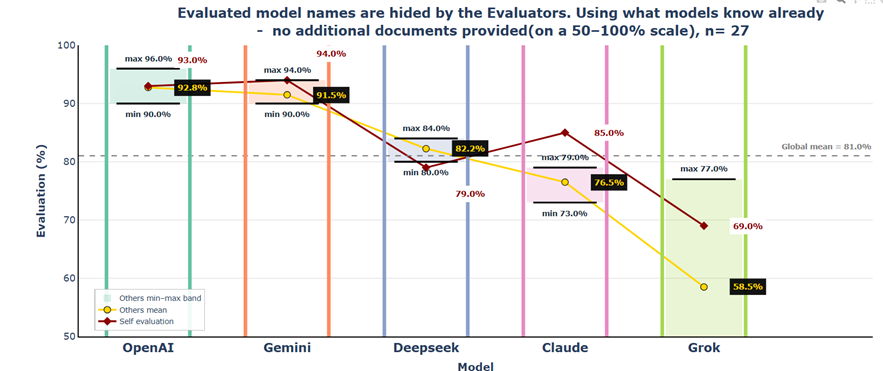
In Scenarios 1 and 2, where neither generators nor evaluators had access to the source document, the generated texts were still rated relatively strongly overall, with average scores around 80%. Building on these two baseline conditions, the main finding is that generator quality has greater influence on evaluation outcomes than evaluator verification.
When evaluators have access to the source material while generators do not, scores drop sharply because errors that previously appeared plausible can now be identified more easily (Scenario 3). When generators receive the source material while evaluators do not, scores rise strongly and evaluator disagreement collapses, showing that higher-quality, grounded outputs are recognized and rewarded even without direct verification (Scenario 4). When both generators and evaluators receive the documentation, average scores change only minimally, but evaluator-specific differences become more visible again (Scenario 5).
These results suggest an asymmetric mechanism: verification primarily acts as an error-detection process. It strongly penalizes inaccurate or incomplete outputs, but adds little once responses are already factually grounded.
Special attention is needed when models evaluate their own outputs in workflows such as self-checking, answer ranking, draft selection, or automated quality scoring, because some models consistently underrate themselves while others consistently overrate themselves, so self-scores can diverge substantially from peer judgment and distort the result the user sees.
These findings have direct practical implications for LLM-as-Judge workflow design: giving source documentation to the generator improves results more than giving it only to the evaluator, and model choice in both roles introduces systematic and reproducible bias. In practical terms, users should prioritize grounding the generating model with accurate source material and treat automated evaluation scores with caution, especially when self-evaluation is involved. If time and resources allow, they should work with multiple models in parallel; if not, they should prefer the models that are most consistently accepted by other models — in Experiment 2, the recommended order is: (1) ChatGPT or Gemini, (3) Claude or DeepSeek, and (5) Grok.
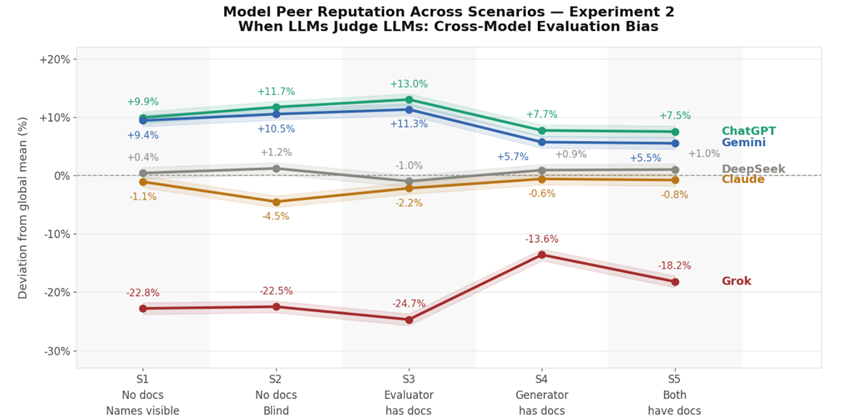
The chart shows a stable reputation hierarchy across all five scenarios: ChatGPT and Gemini stay on top, DeepSeek and Claude remain in the middle and Grok is consistently the weakest outlier. Scenarios 1 and 2 show that even without documentation, scores are already relatively strong and anonymization changes little. Scenario 3 brings the sharpest drop, as evaluator access to the source document reveals weaknesses that previously sounded plausible. Scenario 4 reverses this effect: when generators receive the document, scores rise strongly and evaluator disagreement narrows. Scenario 5 leaves average scores almost unchanged but increases the gap again by penalizing weaker outputs more strongly.
Between Experiment 1 and Experiment 2: Context and Reflections
I am currently running a series of experiments to understand how LLMs evaluate each other's output. My central question is whether the choice of model for text generation carries measurable advantages or disadvantages — particularly given that many of us already use LLMs to create content and to summarise, evaluate, or advise based on that content.
The novelty of this study lies in systematically isolating the effects of evaluator knowledge, generator knowledge, and model identity on cross-model evaluation behaviour.
On the feedback I received
After publishing the first experiment, I received several comments: questions about my model selection, a preference for human judges over LLM judges, and concerns that the rapid evolution of models could quickly render my findings outdated.
Let me address each in turn.
On the question of human versus LLM judges: we all expect, that another human will evaluate our work, whether it is a school assignment, a technical article, or a job application. Our expectation is fair and important. However, I am specifically interested in the growing class of cases where an LLM, not a human, is the first reader. My research does not aim to settle the broader debate about whether LLMs or humans are more appropriate judges in any given context. It simply asks: given that LLM-based evaluation already happens and is increasing, how do these models assess each other's output?
On model selection: my choices were guided by different leaderboards, namely Vellum leaderboard and OpenRouter usage statistics. I used the most widely used models reported at the time of the study. I made one exception with DeepSeek, as I included it as the sole non-US model, representing Chinese and more broadly Asian AI development — chosen over alternatives such as Kimi. For each selected vendor, I used the default model version available through their GUI, whether web or mobile app, to simulate everyday usage patterns.
One observation worth noting: as I used the models programmatically via their respective vendor APIs, there are meaningful differences compared to consumer-facing interfaces. Web and mobile apps are optimised for user experience — lower latency, more seamless file handling, e.g. smoother PDF integration. APIs, by contrast, can be slower and more complex to use. However, my working assumption is that the underlying quality of text generation and evaluation is equivalent across both access modes.
Regarding the concern that my findings may become outdated as models evolve: model evolution is a fact, therefore my experiment represents the models in February–March 2026. But the model evolution offers another opportunity — what would we find if the same experiment is rerun in six months? Will the cross-model evaluation patterns change? Will models become more discriminating, might introduce new evaluative dimensions? Or will the relative patterns remain stable? I expect these questions will deepen our understanding of how LLM judgment functions over time.
Finally, it is worth acknowledging that techniques such as retrieval-augmented generation (RAG) can partially bridge differences in raw model output quality by grounding responses in external knowledge. However, in case of the everyday usage such techniques are not yet part of standard practice.
1. Project Overview
This paper describes the second experiment of comparing evaluation results, which are produced by different LLMs on texts generated by other LLMs. In practice this is an LLM-as-Judge framework, which applied systematically across multiple frontier models. Where Experiment 1 used a topic with broad scholarly consensus (World War II), this experiment shifts to a specialised, product-specific domain of expert knowledge: the DJI Mini 4 Pro drone user manual. The task is to describe the exact steps required to take off a DJI Mini 4 Pro drone.
The central question remains unchanged: what we are looking for is not how objectively correct the generated answers are, but how each model evaluates the others' output. This experiment introduces multiple evaluation rounds per scenario, progressively varying whether the user manual is shared with the generating models, the evaluating models, or both. The added dimension is whether providing the source document — to the generator, the evaluator, or both — alters the cross-model scoring patterns observed in Experiment 1.
Disclaimer: This is a specific experiment with a defined scope — particular models, versions, topic, and prompts. It was conducted to the best of the author's knowledge and abilities, and all methods, prompts, and configurations are fully transparent and available throughout this paper.
Practical Recommendation: When working on anything consequential, consider using multiple models in parallel — if the opportunity exists to do so.
2.1 Task Design
All five models — ChatGPT, Claude, DeepSeek, Gemini, and Grok — were asked the same question: prepare a list with all exact steps required to take off a DJI Mini 4 Pro drone, with a strict 500-word limit. This topic was chosen because it requires knowledge of a specific, proprietary product manual that the models are unlikely to have encountered in their training data — making it a genuine test of expert knowledge retrieval versus reliance on general reasoning. This remains an assumption; it cannot be verified directly, as the training data of frontier models is not publicly disclosed.
I've created five scenarios to assess the potential effect of sharing or holding back the extra knowledge across the generation and evaluation phases. In each scenario, the same five models both generated answers and evaluated each other's outputs.
2.2 Experimental Design — Five Scenarios
The five scenarios form a structured matrix varying two dimensions: whether the source document (DJI Mini 4 Pro User Manual) was provided to the generating model, the evaluating model, both, or neither. An additional control dimension — whether model names were visible to evaluators — was tested in the first two scenarios.
2.3 Model Selection
The same five models as Experiment 1 were used, queried directly through their respective vendor APIs. Model selection was based on the Vellum leaderboard and OpenRouter usage statistics at the time of the study, with DeepSeek included as the sole non-US model.
| Model Label | Model String | API Provider |
|---|---|---|
| Gemini | gemini-3-flash-preview | Google Gemini API |
| OpenAI | gpt-5.2 | OpenAI API |
| DeepSeek | deepseek-chat (v3.2) | DeepSeek API |
| Claude | claude-sonnet-4-20250514 / claude-sonnet-4-5-20250929 | Anthropic API |
| Grok | grok-4-1-fast-reasoning | xAI API |
Note: Claude's model version was updated mid-experiment. Scenario 1 uses claude-sonnet-4-5-20250929; Scenarios 2–5 use claude-sonnet-4-20250514.
2. Scenario 1 — Baseline Evaluation without External Reference Material
3.1 Generation Phase: Observations on the Drone Take-off Task
Runtime and Output Size
Before analysing the content of the generated instructions, noticeable variation appeared in response latency and output length across the tested models. The measurements reflect API-based generation recorded during the experiment.
| Model Label | Latency via API | Output Size | Observations |
|---|---|---|---|
| Gemini | ~6.5 sec | ~390 words | Fastest model while producing the most detailed instructions |
| OpenAI | ~10 sec | ~330 words | Moderate latency with consistent mid-length outputs |
| DeepSeek | ~18 sec | ~300 words | Slowest model despite relatively concise responses |
| Claude | ~15 sec | ~380 words | Balanced latency with detailed responses |
| Grok | ~10 sec | ~265 words | Fast response time but shortest outputs |
The generated instructions showed strong structural convergence, typically following a three-stage procedural pattern: physical preparation, system readiness checks, and execution of the take-off procedure. While the responses differed in style — ranging from manual-like step-by-step instructions to more contextual or tutorial-oriented explanations — all models produced technically coherent guidance, with differences mainly reflecting how procedural information was structured and emphasised.
Sometimes Grok's outputs ended with a reference to the official DJI website: "Total words: 298. Fly safe! (Official DJI manual for visuals: dji.com/mini-4-pro/downloads)". Since the experiment did not enable any external search tools or web-access capabilities during the API call, this behaviour might be the result of the model generating a plausible reference based on patterns present in its training data rather than performing a live web query. Btw the link was correctly presented by Grok and it is up and running. Interestingly none of the other models cited this web link.
3.2 The Evaluation Phase
3.2.2.1 Cross-Model Scoring Matrix
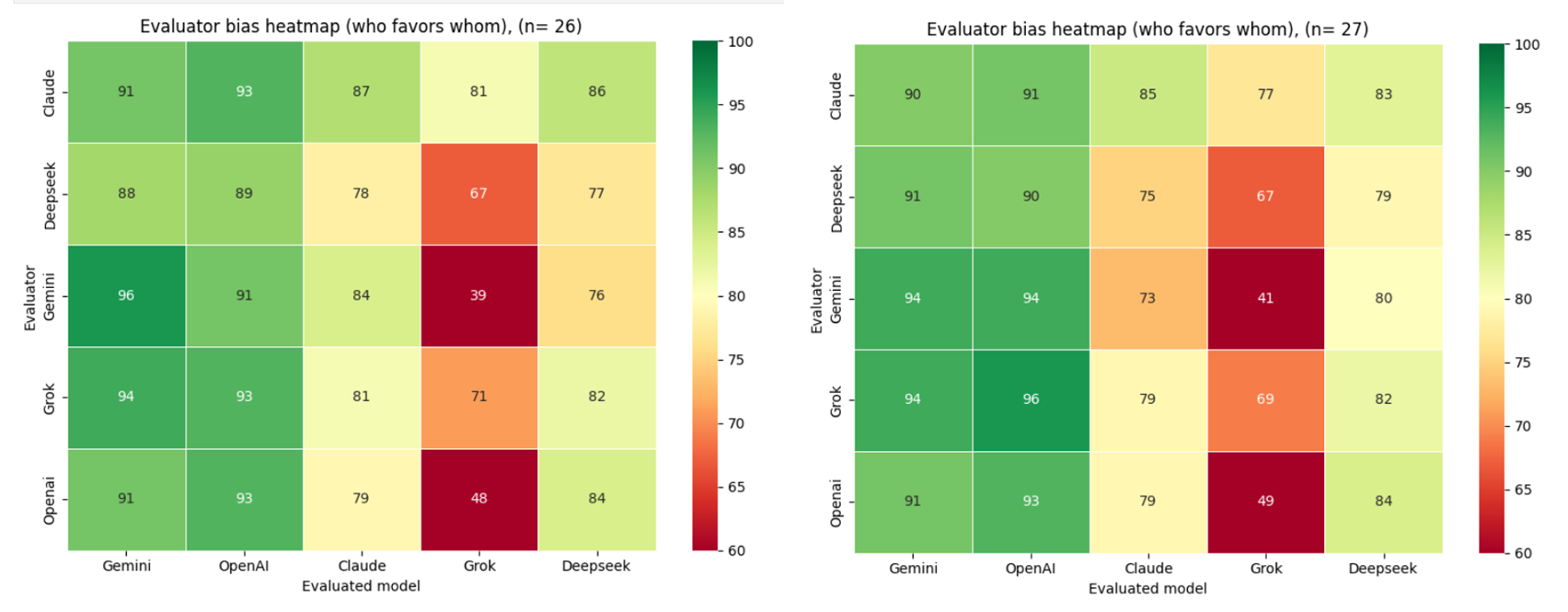
The heatmap below shows the full cross-model scoring matrix: how each model scored every other model, including itself, aggregated across all 26 evaluation runs.
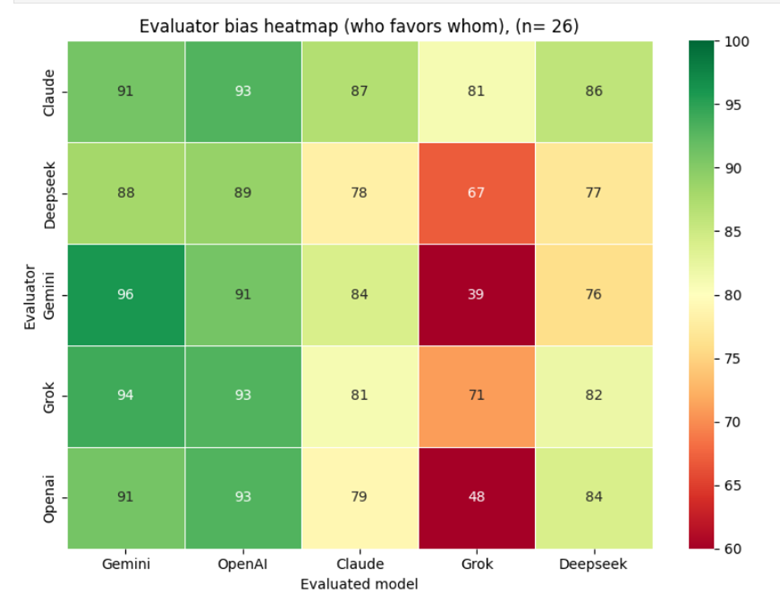
Across all 26 cycles, aggregate scores are high overall, with ChatGPT and Gemini emerging as the two consistently top-rated models by their peers. Authors using Grok for text generation should be aware that peer models score their output measurably lower on average — a structural pattern, not a statistical artefact.
3.2.2.2 Cross-Experiment Observations
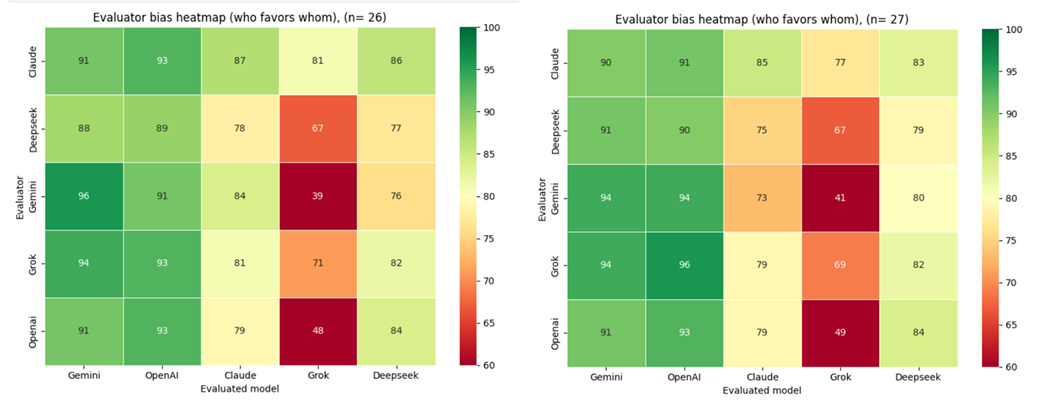
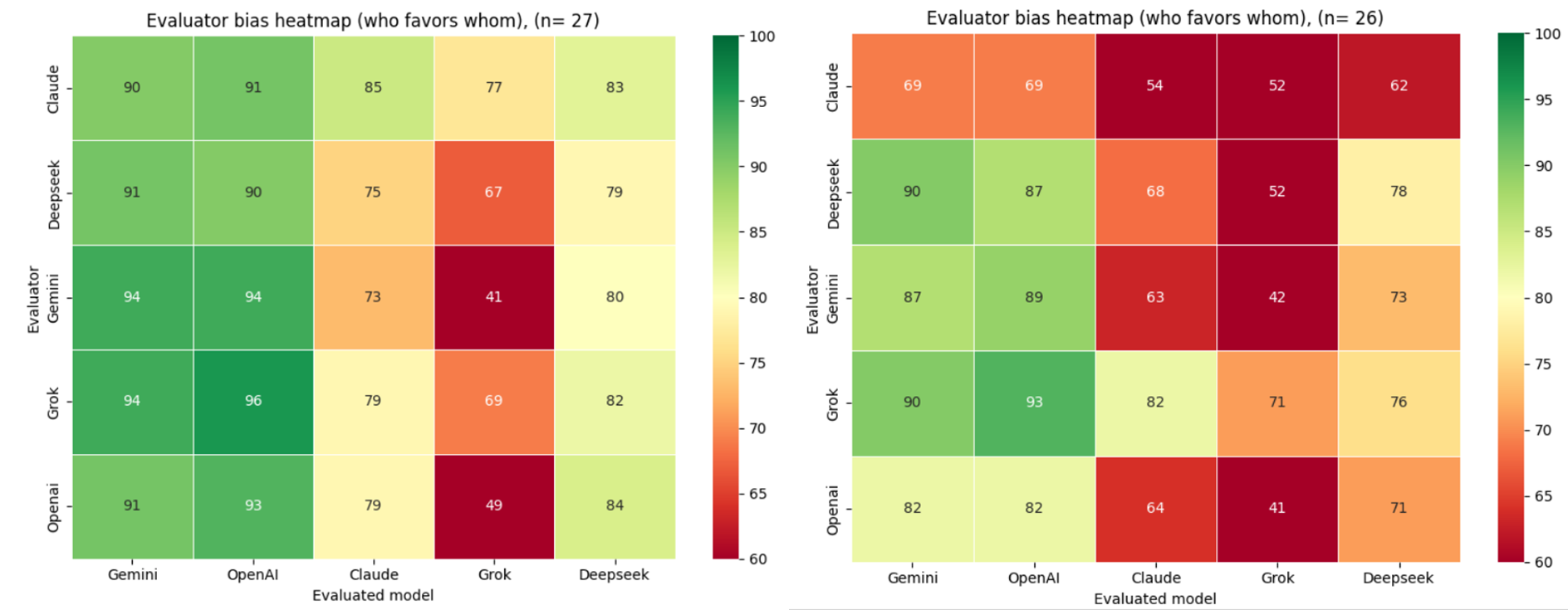
The left matrix (Experiment 1, n=29) reflects cross-model evaluation on a common knowledge domain — World War II — where all models are assumed to share a broadly similar academic and scholarly foundation. The right matrix (Experiment 2, n=26) shifts to a domain of specialised expert knowledge — DJI Mini 4 Pro drone operation — where no established academic or scholarly consensus exists, and models are unlikely to have been trained on the specific proprietary content required to answer accurately.
Comparing the two heatmaps reveals a consistent pattern alongside a domain-dependent divergence. Gemini and OpenAI maintain the highest peer reputation across both experiments, suggesting that evaluator preference for these models is stable regardless of knowledge domain.
The most significant structural difference between the two matrices is the score spread. In Experiment 1 (World War II), scores cluster tightly in the upper range, reflecting broad evaluator agreement in a domain where all models presumably share a common academic knowledge base. In Experiment 2 (DJI Mini 4 Pro), the spread widens considerably, with individual cells reaching as low as 39%. This indicates that domain specialisation amplifies inter-model differentiation — models that perform comparably on common knowledge tasks diverge markedly when the task requires specific proprietary expertise.
Grok shows the most pronounced domain sensitivity, receiving the lowest scores in Experiment 2 by a substantial margin, particularly from Gemini and OpenAI. This suggests that Grok's responses were perceived as less technically credible in the expert knowledge domain, a pattern not visible in the common knowledge setting.
3.2.2.3 Evaluator Strictness
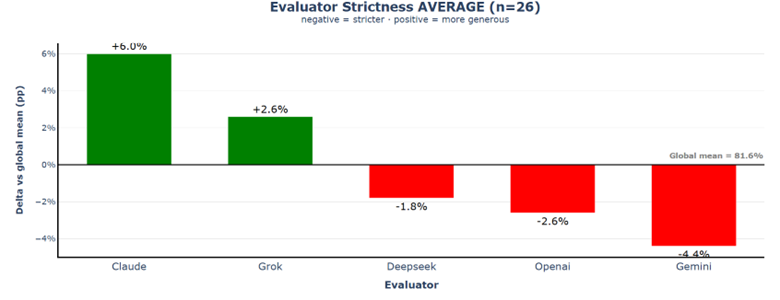
Claude appears as the most lenient evaluator (+6.0% above the mean), followed by Grok (+2.6%), while Gemini is the strictest evaluator (−4.4%), with OpenAI (−2.6%) and DeepSeek (−1.8%) also scoring slightly below the global average of 81.6%. The total spread between the most lenient and strictest evaluator is roughly 10%, indicating that evaluator behaviour alone can significantly influence the relative ranking of the models.
3.2.2.4 Model Reputation
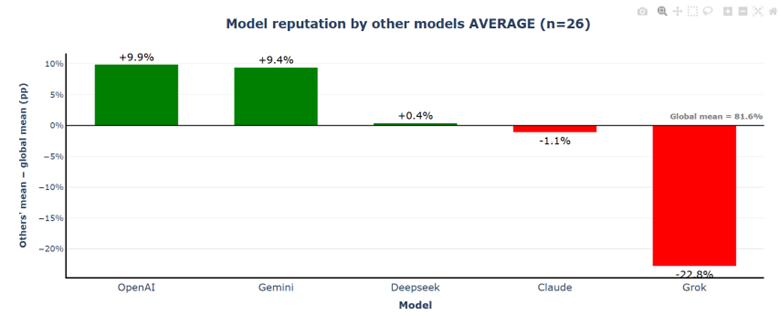
OpenAI and Gemini clearly stand out, scoring about +9.9% and +9.4% above the mean, respectively, while DeepSeek (+0.4%) and Claude (−1.1%) remain close to the overall average. In contrast, Grok appears as a strong negative outlier (−22.8%), creating a total spread of more than 30% between the highest- and lowest-rated models in the peer evaluation.
3.2.2.5 Self-Assessment vs. Peer Assessment
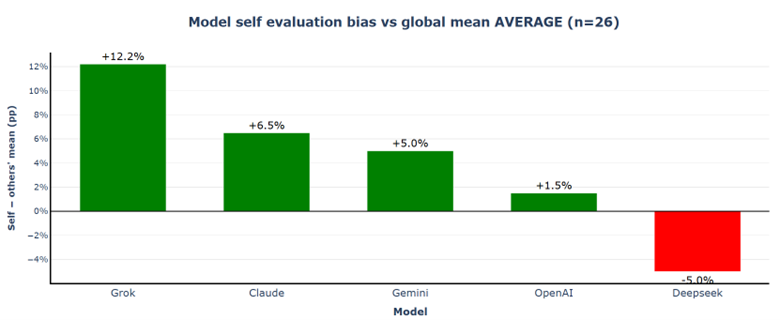
Grok shows the largest positive deviation (+12.2%), indicating a strong tendency to rate its own output significantly higher than its peers do. Claude (+6.5%) and Gemini (+5.0%) also display notable positive self-bias, while OpenAI remains relatively close to peer consensus (+1.5%). In contrast, DeepSeek is the only model that scores itself lower than the peer average (−5.0%). Self-evaluation bias is model-specific and systematic rather than random.
3.2.2.6 Consolidated View
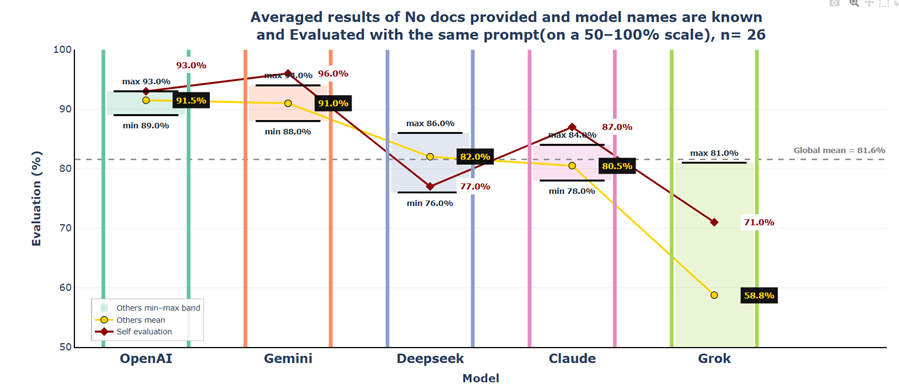
OpenAI and Gemini clearly stand out with the highest peer mean scores (both around 91%) and relatively narrow evaluation bands. In contrast, DeepSeek and Claude occupy a middle position with peer means around 80%–82%. Grok appears as the strongest outlier: its peer mean score is substantially lower (58.8%) and its evaluation band remains well below the global average.
3.3 Conclusions
The spread between the highest- and lowest-rated models exceeds 30 percentage points in peer reputation, which is large enough to have practical consequences in automated evaluation pipelines where LLM-generated content is screened, ranked, or filtered without human review. OpenAI and Gemini consistently achieved the strongest peer reputation, combined with relatively stable evaluation ranges and well-aligned self-assessments. Grok shows a pronounced positive self-evaluation bias, while DeepSeek tends to rate its own output more conservatively. Claude occupies a middle position with relatively balanced peer evaluations but moderate variance in scoring.
3. Scenario 2 — Name Blind Control
This scenario was prepared to answer the question: does the evaluation outcome change when the evaluator models do not know which generator produced each answer? Scenario 2 removes this information, replacing model names with anonymous labels (Answer A–E), to isolate the effect of generator identity on scoring behaviour.
4.2.2.1 Cross-Model Scoring Matrix
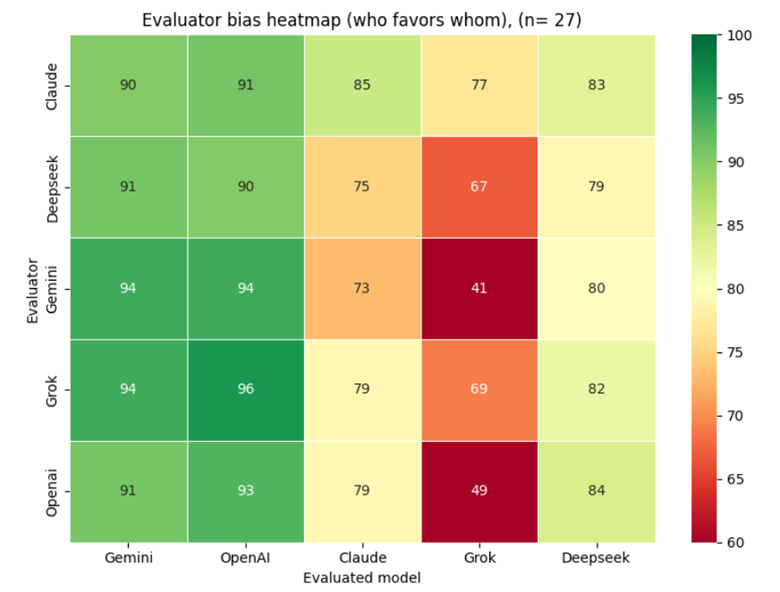
When generator identities were hidden from evaluators, the overall scoring pattern remained largely consistent with Scenario 1 — Gemini and OpenAI continue to receive the highest peer scores, while Grok remains the lowest-rated model across all evaluators. This suggests that evaluator bias is driven primarily by response quality rather than model reputation.
4.2.2.2 Scenario 1 vs. Scenario 2 Observations
One subtle shift is worth noting: Claude's scores drop when names are hidden, with Gemini's score for Claude falling from 84% to 73% — an 11% difference across 27 runs — suggesting that Claude benefits from name recognition specifically in Gemini's evaluation. Conversely, Grok's scores show no meaningful change when anonymous.
4.2.2.3 Evaluator Strictness
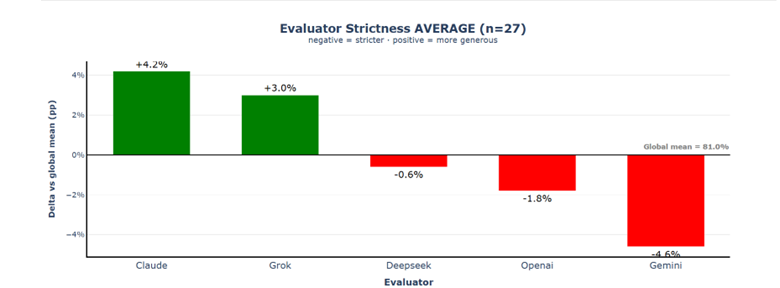
Claude remains the most lenient evaluator in both scenarios, its leniency drops from +6.0% to +4.2%. The overall spread between the most lenient and strictest evaluator narrows from 10.4% to 8.8%, suggesting that hiding generator model names didn't influence the bias across models.
4.2.2.4 Model Reputation
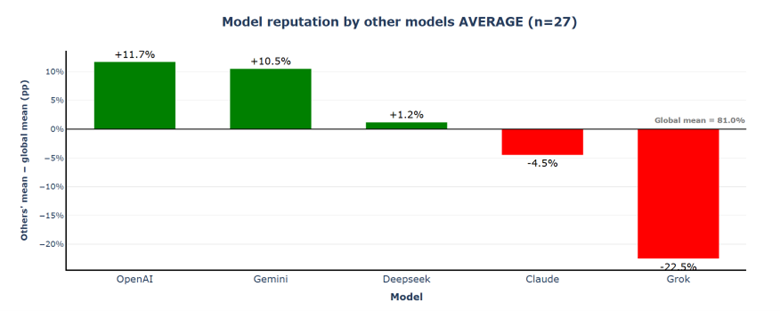
OpenAI jumps from +9.9% to +11.7%, and Gemini rises from +9.4% to +10.5% above the global mean. Claude's negative reputation worsens from −1.1% to −4.5%, thanks to Gemini's harsher blind assessment; and Grok remains deeply undervalued with −22.5%.
4.2.2.5 Self-Assessment vs. Peer Assessment
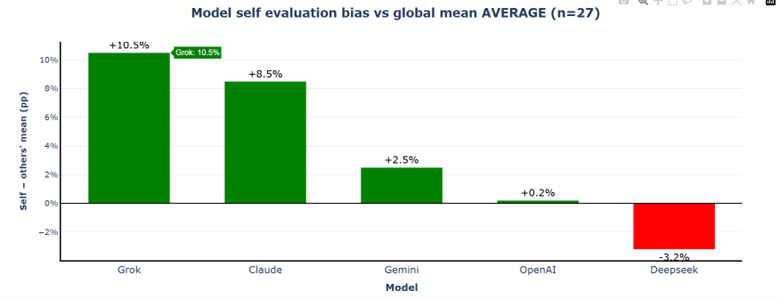
Grok's extreme self-favoritism drops from +12.2% to +10.5%, however Claude's self-bias increases from +6.5% to +8.5%. OpenAI shifts to near-perfect calibration (+0.2%). The spread between the most self-favoring (Grok) and most self-critical (DeepSeek) model narrows from 17.2 to 13.7 percentage points, suggesting that without recognising themselves, models become more objective when evaluating their own outputs.
4.2.2.6 Consolidated View
4.3 Conclusions
The central finding of Scenario 2 is that concealing model identity during evaluation substantially reduces inter-model bias compared to Scenario 1. The spread in evaluator strictness narrows from 10.4% to 8.8% points, and self-evaluation bias decreases from 17.2% to 13.7% points. Despite this overall moderation, the reputation hierarchy remains largely intact. OpenAI and Gemini continue to dominate with peer means around 91%–93%. The most dramatic shift occurs in the middle tier: DeepSeek's reputation advantage over Claude widens significantly from 1.5% to 5.7%, driven largely by Gemini's harsh assessment of Claude when model names are hidden.
4. Scenario 3 — Evaluator Has Expert Knowledge
This scenario aims to answer the following question: how do the evaluators' outcomes change, when they have the expert knowledge (user manual of the drone) available during the evaluation phase, but the generators still don't have the specific knowledge available. One obvious assumption might be, that the models would be stricter with their evaluations, because they have the extra knowledge the generators don't have.
While some models (such as Gemini and Claude) advertise native PDF support through their APIs, this capability proved unreliable when processing complex user manuals containing diagrams, safety graphics, and mixed layouts. To ensure consistent conditions across all five models, all evaluators received the same plain-text version of the DJI Mini 4 Pro manual.
Each evaluation call processes approximately 50,000–58,000 tokens, consisting primarily of the 204,613-character user manual (~51,000 tokens), evaluation prompts (~1,500 tokens), and JSON output (~500–2,000 tokens). OpenAI: 51,332 · DeepSeek: 51,978 · Grok: 52,242 · Gemini: 58,190 · Claude: 58,511 tokens. All models handled this token volume without issue.
5.2.2.1 Cross-Model Scoring Matrix
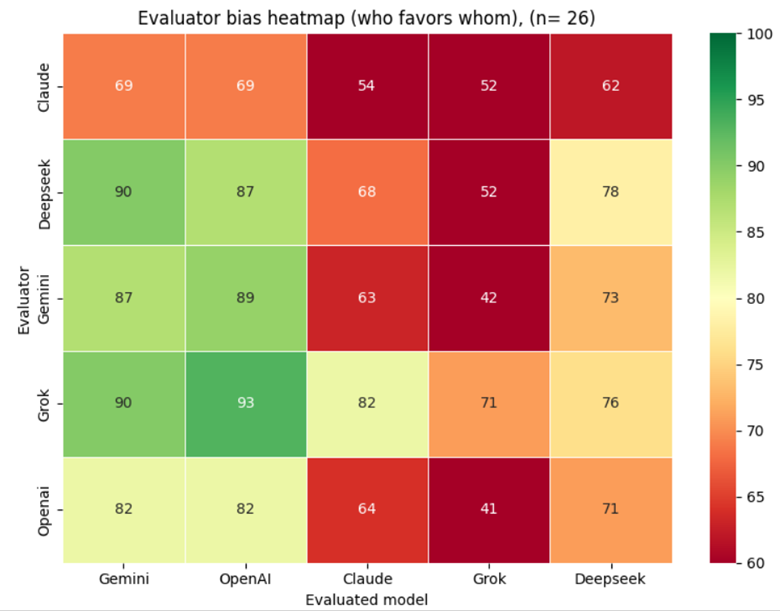
The majority of the values in the matrix dropped significantly from the previous Scenario 2. Gemini and OpenAI receive the highest scores across all evaluators (69%–93% range), while Grok consistently receives the lowest ratings (41%–71%), with particularly harsh judgments from Gemini (42%) and OpenAI (41%). DeepSeek occupies a middle position (62%–78%), and Claude scores between 54%–82% across evaluators.
5.2.2.2 Scenario 2 vs. Scenario 3 Observations
Claude shows the most extreme shift in both roles. As a generator, it experiences the largest drop in scores. At the same time, Claude also becomes the strictest evaluator. Its scoring drops by around 20% in almost every case, from the 77%–91% range to the 52%–69% range. All models (except Grok) penalize Claude heavily overall, with Claude receiving in total 29% lower evaluations.
5.2.2.3 Evaluator Strictness
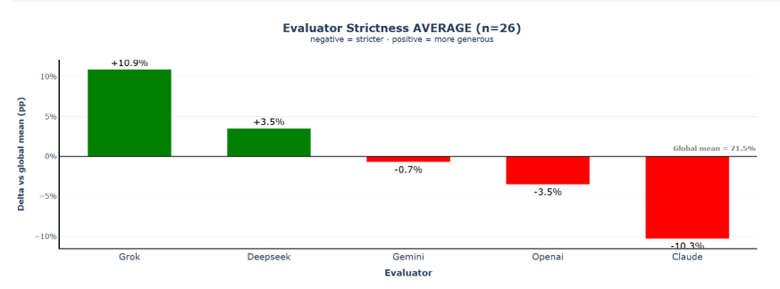
The global mean drops substantially by 10%, to 71.5%. Claude drops to −10.3% (compared to +4.2% in Scenario 2). Grok emerges as the most lenient evaluator at +10.9% above the global mean. The evaluator strictness spread increases to 21.2% (from 8.8% in Scenario 2).
5.2.2.4 Model Reputation
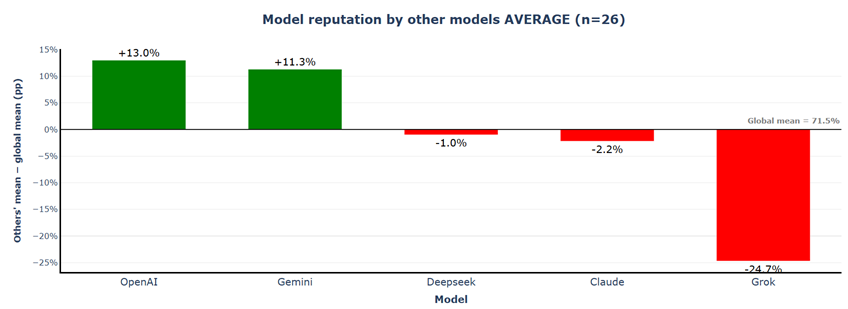
Despite the 10% drop in absolute scores, the model reputation hierarchy remains virtually unchanged. OpenAI and Gemini maintain their dominant positions at +13.0% and +11.3% above the global mean. Grok remains the most undervalued model at −24.7%, and Claude stays in negative territory at −2.2%.
5.2.2.5 Self-Assessment vs. Peer Assessment
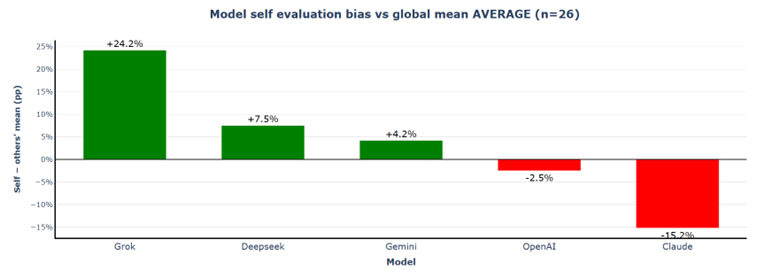
Grok's self-favouritism more than doubles from +10.5% to +24.2%. Most interestingly, Claude becomes significantly more self-critical, now at −15.2% (compared to +8.5% in Scenario 2) — a swing of 23.7 percentage points. The self-evaluation bias spread explodes to 39.4% (from 13.7% in Scenario 2).
5.2.2.6 Consolidated View
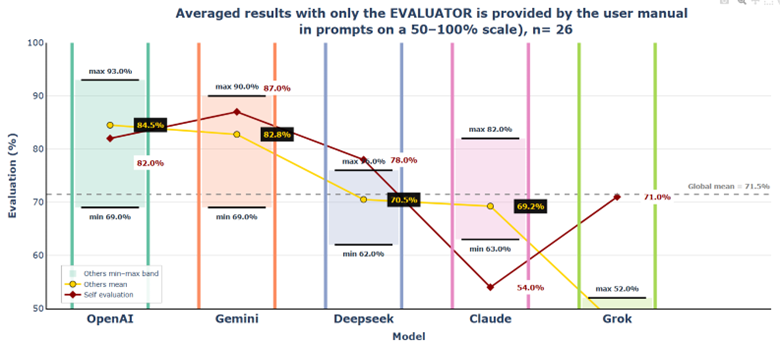
5.3 Conclusions
Providing evaluators with source documentation fundamentally transforms evaluation dynamics while preserving the core reputation hierarchy. Scores drop by approximately 10 percentage points, yet OpenAI and Gemini retain their top-tier status, and Grok remains the lowest-rated model. Access to ground truth amplifies rather than reduces evaluator behaviour differences. The evaluator strictness spread explodes from 8.8% to 21.2%, and self-evaluation bias range widens from 13.7% to 39.4% points.
5. Scenario 4 — Generator Has Expert Knowledge
Scenario 4 seeks to answer the question: how do evaluator outcomes change when generators have access to the drone user manual but evaluators do not? One assumption might be that evaluations would be much higher than in Scenario 3. It would be interesting to see whether evaluators can recognize and appreciate higher-quality answers without having the source material themselves.
6.1 Generation Phase — Runtime and Output Size
| Model Label | Latency via API | Output Size | Observations |
|---|---|---|---|
| Gemini | ~8 sec | ~390 words | Fastest model while producing relatively detailed instructions |
| OpenAI | ~12 sec | ~350 words | Moderate latency with consistent mid-length outputs |
| DeepSeek | ~19 sec | ~300 words | Highest latency despite relatively concise responses |
| Claude | ~16 sec | ~380 words | Balanced latency and relatively detailed responses |
| Grok | ~15 sec | ~260 words | Shortest responses despite relatively high token usage |
Key Finding 1: Adding approximately 50,000 input tokens (the user manual) resulted in negligible latency increases across all models (<1 second). Modern LLMs handle large context windows efficiently, with generation speed primarily determined by output length rather than input size.
Key Finding 2: The repeated runs demonstrate that model-specific behaviour is stable and reproducible, with each model consistently applying its characteristic style (Gemini = structured/manual-like, OpenAI = contextual, DeepSeek = concise, Claude = balanced, Grok = tutorial-like).
6.2.1.1 Cross-Model Scoring Matrix
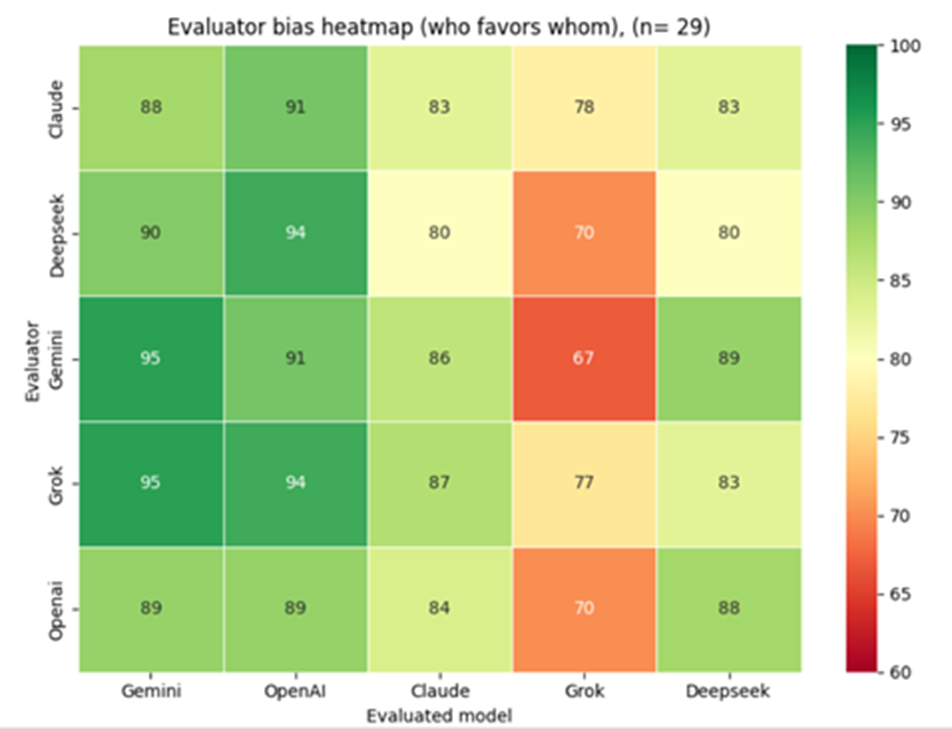
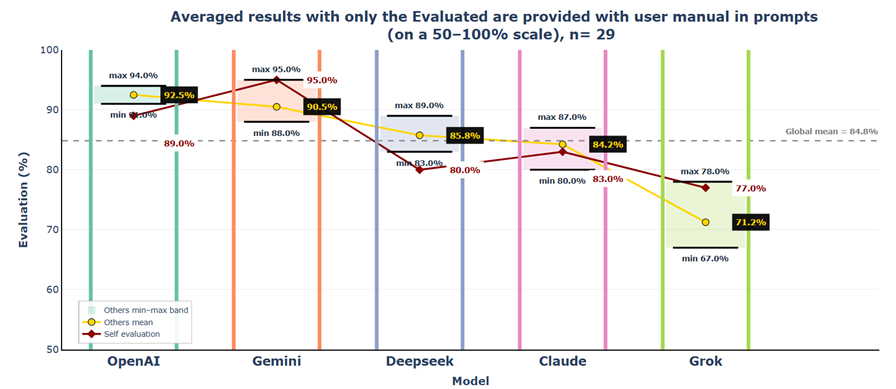
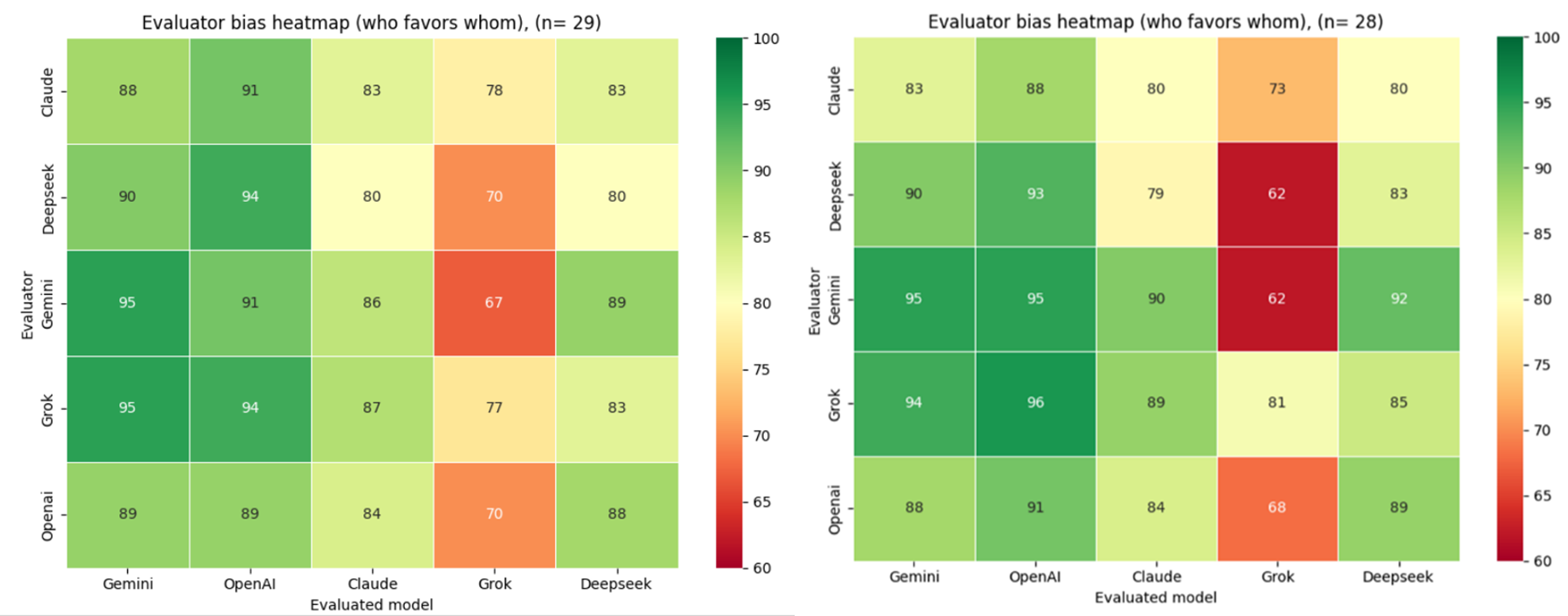
When generators have access to source documentation, but evaluators do not, scores rise dramatically across the board compared to Scenario 3. Gemini and OpenAI dominate with scores in the 89%–95% range across all evaluators. Claude and DeepSeek receive mid-tier evaluations (80%–89%), while Grok remains the lowest-rated at 67%–78%. Scores rise moderately but consistently by 5%–15% compared to Scenario 2, suggesting that evaluators assign higher scores to higher-quality, factually grounded outputs even without being able to verify the information themselves.
6.2.1.2 Scenario 3 vs. Scenario 4 Observations
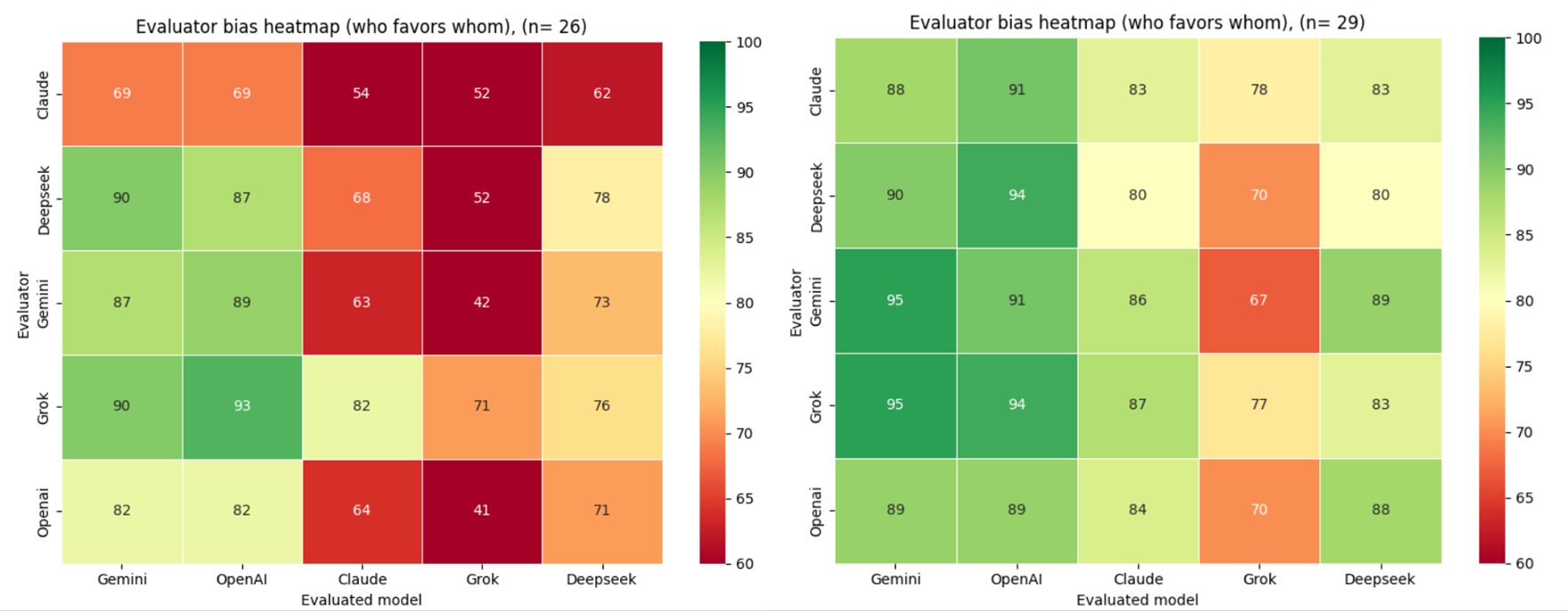
Grok's scores surge from 41%–71% (Scenario 3) to 67%–78% (Scenario 4), and Claude jumps from 54%–82% to 80%–87%. Providing generators with accurate source material elevates output quality so substantially that evaluators without access to that material still rate responses 15%–25% higher, indicating that models are able to recognize and reward higher-quality outputs based on internal signals of plausibility and correctness, even without direct access to ground truth.
6.2.1.3 Evaluator Strictness
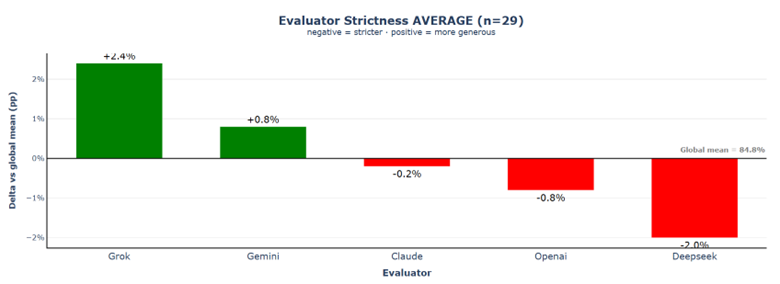
The global mean rises sharply to 84.8%, and the strictness spread collapses from 21.2% to just 4.4%. Claude shifts from extreme strictness (−10.3%) to near-perfect calibration (−0.2%). When generators rely on factual source material, the resulting responses leave little room for subjective interpretation, reducing uncertainty and limiting the evaluators' "degrees of freedom."
6.2.1.4 Model Reputation
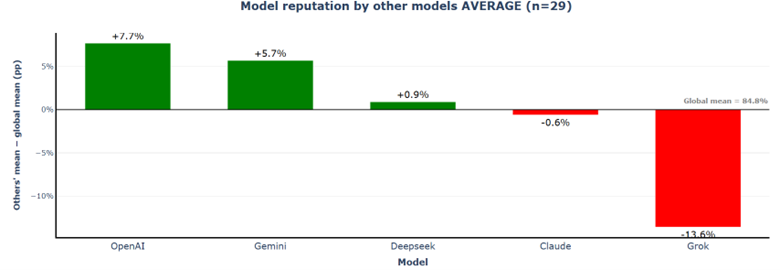
The reputation hierarchy remains stable: OpenAI (+7.7%) and Gemini (+5.7%) at top, DeepSeek (+0.9%) and Claude (−0.6%) near global mean, Grok (−13.6%) at bottom. The reputation spread narrows significantly from 37.7% to 21.3%.
6.2.1.5 Self-Assessment vs. Peer Assessment
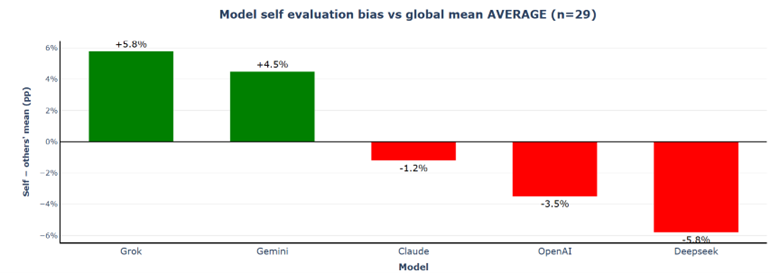
Self-evaluation bias patterns compress dramatically: the spread narrows from 39.4% to just 11.6%. Grok's self-favouritism drops from +24.2% to +5.8%, Claude's extreme self-criticism reverses from −15.2% to near-perfect calibration at −1.2%.
6.2.1.6 Consolidated View
6.3 Conclusions
Providing generators with source documentation while withholding it from evaluators produces the highest scores and strongest evaluator consensus observed across all scenarios. Evaluators can not only reliably detect quality differences in outputs without verification material, but also recognize and reward the quality improvement that results from generator access to source documentation.
The practical implication: providing source documentation to generators is more valuable than providing it to evaluators — it elevates output quality detectably, reduces evaluator disagreement, and produces more stable scoring patterns, even when evaluators cannot verify claims against ground truth.
6. Scenario 5 — Both Have Expert Knowledge
In this final scenario, both generators and evaluators have access to the specific expert knowledge — the user manual of the DJI Mini 4 Pro drone. The key question: which force dominates — the generators' high-quality answers that evaluators recognize and reward, or the evaluators' strict assessments when they can verify what the correct answer should have been?
7.2.1.1 Cross-Model Scoring Matrix
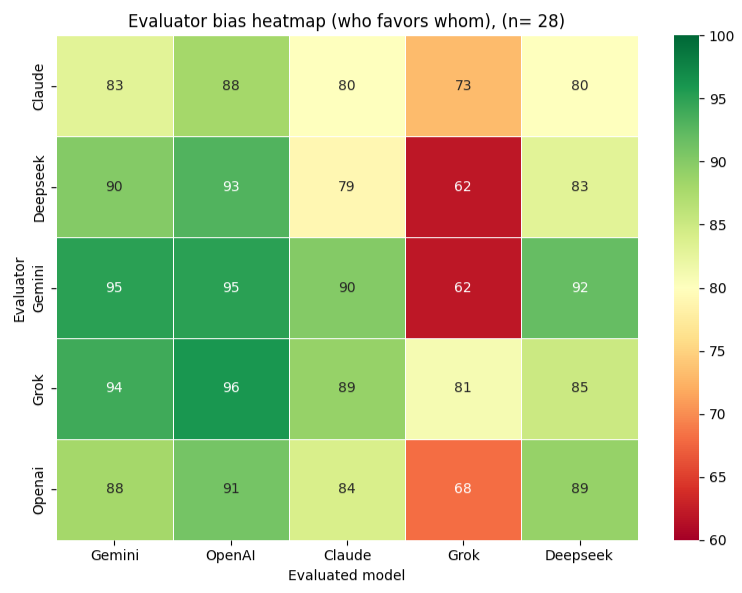
When both generators and evaluators have access to source documentation, scores remain nearly identical to Scenario 4 (global mean 84.4% vs 84.8%), demonstrating that evaluator access to verification material has negligible impact when generators produce factually grounded outputs. Grok experiences the only notable decline to 62%–81%, with particularly harsh judgments from Gemini (62%) and DeepSeek (62%) when both can verify against ground truth.
7.2.1.2 Scenario 4 vs. Scenario 5 Observations
7.2.1.3 Evaluator Strictness
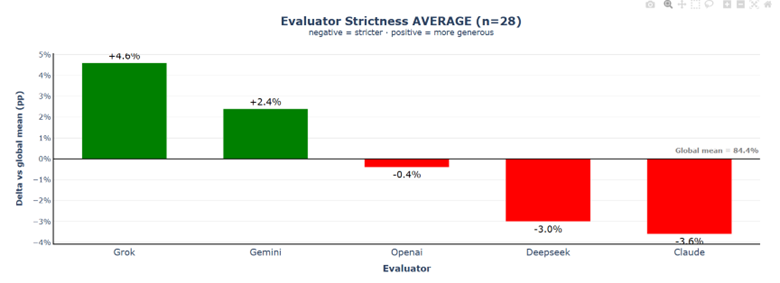
The evaluator strictness spread nearly doubles from 4.4% to 8.2%, revealing that verification capability reintroduces individual evaluator bias patterns. Claude reverts to significant strictness (−3.6%), while Grok and Gemini become more lenient (+4.6% and +2.4% respectively).
7.2.1.4 Model Reputation
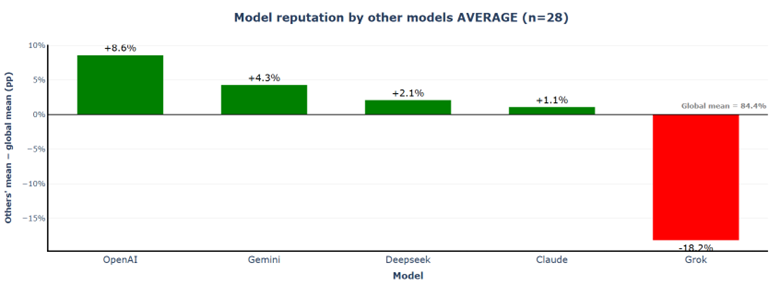
The reputation spread widens from 21.3% to 26.8%, driven primarily by Grok's significant decline from −13.6% to −18.2%. Other models remain relatively stable: OpenAI +8.6%, Gemini +4.3%, DeepSeek +2.1%, Claude +1.1%.
7.2.1.5 Self-Assessment vs. Peer Assessment
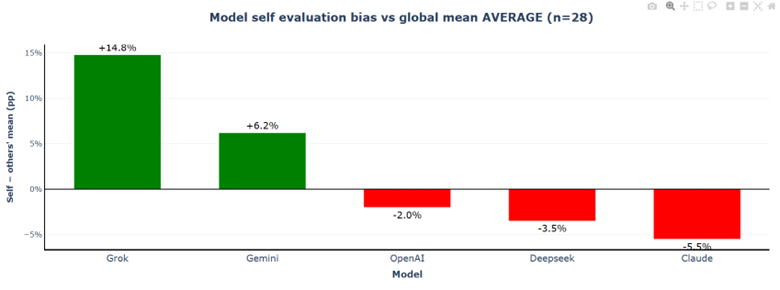
The self-evaluation bias spread nearly doubles from 11.6% to 20.3%. Grok's self-favouritism explodes from +5.8% to +14.8%, while Claude's self-criticism intensifies from −1.2% to −5.5%. Grok evaluates its own responses using the same logic that generated them and therefore misses certain errors, while other models — especially when verification is available — apply stronger error detection.
7.2.1.6 Consolidated View
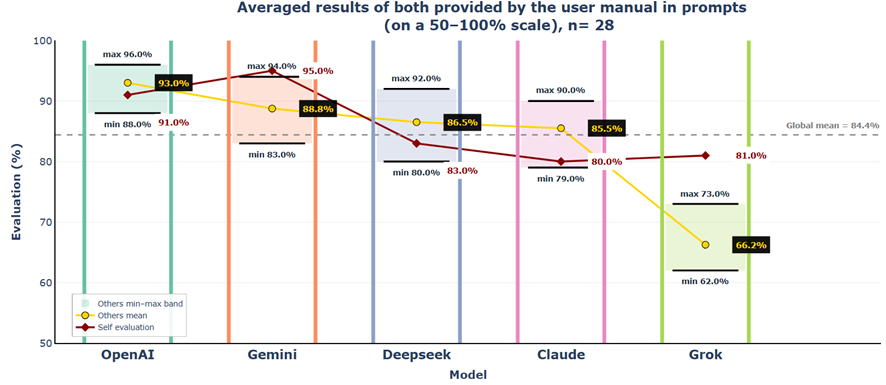
7.3 Conclusions
Adding evaluator verification to an already grounded generation process (Scenario 4→5) produces minimal change in average scores but makes evaluator-specific bias patterns more visible. Scores remain nearly unchanged (84.8% → 84.4%, −0.4pp), while evaluator strictness spread increases, reputation spread widens, and self-evaluation bias spread nearly doubles. Access to ground truth does not standardize evaluation — it makes differences in evaluator behaviour more pronounced.
Across Scenarios 2–5, generator quality is the primary driver of evaluation outcomes, while evaluator verification acts asymmetrically as an error-detection mechanism. The practical implication: generator access to documentation appears to be the primary driver of evaluation outcomes. Providing verification material to evaluators when generators already have access yields limited impact on average scores.
Appendix A — Generator Prompts
The following single user prompt was sent to all five models during the generation phase. No system prompt was used.
Appendix B — Scenario 1: Structural Characteristics of the Generated Instructions
C.1 Procedural Structure
Across all models, the responses showed a strong structural convergence. Despite stylistic differences, nearly all outputs followed a similar three-stage procedural template: (1) physical preparation of the drone, (2) system readiness checks (power-on, GPS acquisition, safety verification), (3) execution of the takeoff procedure. This structural convergence suggests that large language models share a broadly similar internal representation of procedural tasks.
C.2 Instruction Style Differences
Gemini consistently produced highly explicit, step-by-step instructions resembling a technical manual. OpenAI responses tended to integrate operational advice directly into the procedural flow, often including contextual guidance such as safe launch location selection. DeepSeek generated the most concise procedural explanations, focusing on essential steps. Claude typically produced balanced responses combining procedural steps with safety reminders and operational checks. Grok tended to adopt a tutorial-like approach, integrating regulatory reminders, troubleshooting advice, and additional contextual information alongside the basic takeoff procedure.
C.3 Scope Management and Output Consistency
Some responses focused strictly on the physical steps required to launch the drone, while others expanded the scope to include additional safety checks, regulatory considerations, or troubleshooting advice. Despite the stylistic variation, all models produced technically coherent and usable instructions. The differences become most visible only when the outputs are compared side by side.
Appendix C — Evaluation Prompts I (Scenario 1)
System Prompt of the Evaluator Role
User Prompt of the Evaluator Role (Scenario 1 — Names Visible)
Appendix D — Evaluation Prompts II (Scenario 2 — Anonymous)
Appendix E — Scenario 4: Structural Characteristics of the Generated Instructions
Across both runs for each model, the generated instructions showed high intra-model consistency. Each model reproduced nearly identical structural patterns and instruction styles between runs, with only minor variations in phrasing or level of detail. The same three-stage procedural structure remained dominant: (1) physical preparation, (2) system readiness checks, (3) takeoff execution. This indicates that the generation process is highly deterministic at the structural level, even when responses are regenerated independently.